The Reality Shift in Vulnerability Management



The Signal Behind the Noise
Skepticism toward AI security announcements is reasonable. The industry has seen enough hype. But this shift is not about positioning. It is about volume, capability, and what you can measure in your own programme.
We are entering a phase where vulnerability remediation becomes the dominant constraint. Whether AI is the trigger or the accelerator does not change the outcome. The numbers are already forcing the transition. This argument does not depend on a single model launch, vendor claim, or announcement cycle. It reflects three separate but converging pressures: disclosure volume is rising, exploit pressure is rising, and remediation capacity is not scaling with either.
The deeper shift we are seeing is operational. Discovery is becoming easier to scale than remediation. Finding more issues is increasingly more efficient and repeatable. However validating, owning, fixing, and safely shipping changes is not.
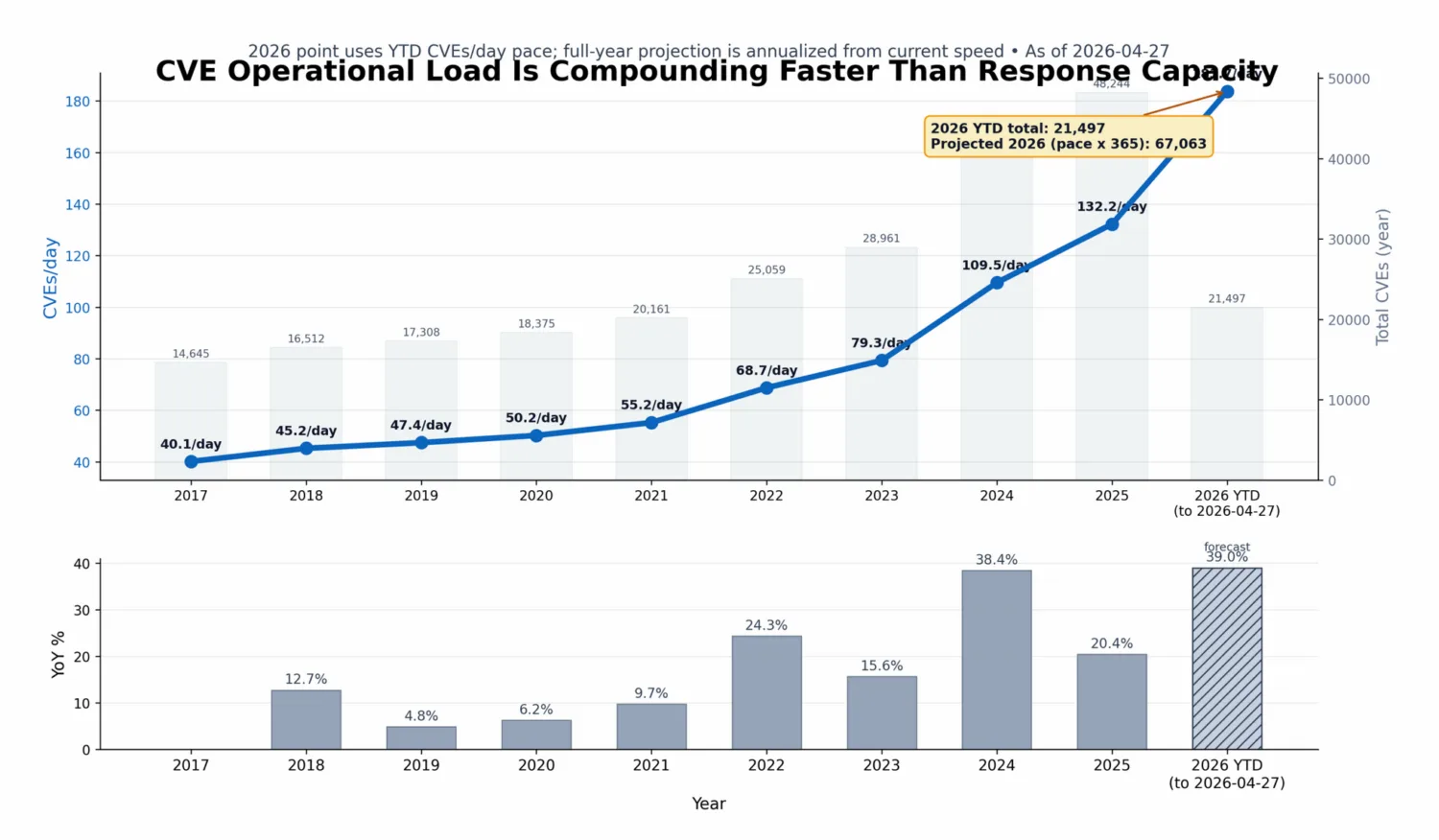
In 2021, roughly 55 CVEs were published per day. By 2025, that number increased to around 130 per day (based on CVE Program annual totals and day-normalized rates). This is only what is formally tracked. It excludes internal discoveries, undisclosed issues, and findings that never reach the CVE system.
The question is no longer whether vulnerabilities can be found. The practical constraint is whether remediation can scale.
That question is already being answered in practice. Most organisations cannot.
AI Is the Inflection Point, Not the Beginning
There is ongoing debate about whether named AI systems are overhyped. There is also recurring debate about attribution: was a given CVE found by one model, another model, or a human researcher. That discussion misses the underlying trend in the data.
You can see the shift in public datasets regardless of vendor branding. CVE Program yearly totals rose from 20,161 (2021) to 48,244 (2025).
NIST describes the same pressure trend directly:
“Submissions during the first three months of 2026 are nearly one-third higher than the same period last year.”
—NIST, April 2026
The point is not one tool or model (Mythos). The baseline has already been shifting for at least the past 6 to 12 months. Mozilla framed this shift in practical engineering terms, not as a story about one vendor:
“We view this as clear evidence that large-scale, AI-assisted analysis is a powerful new addition in security engineers’ toolbox. Firefox has undergone some of the most extensive fuzzing, static analysis, and regular security review over decades. Despite this, the model was able to reveal many previously unknown bugs. This is analogous to the early days of fuzzing; there is likely a substantial backlog of now-discoverable bugs across widely deployed software.”
—Mozilla, Hardening Firefox with Anthropic’s Red Team
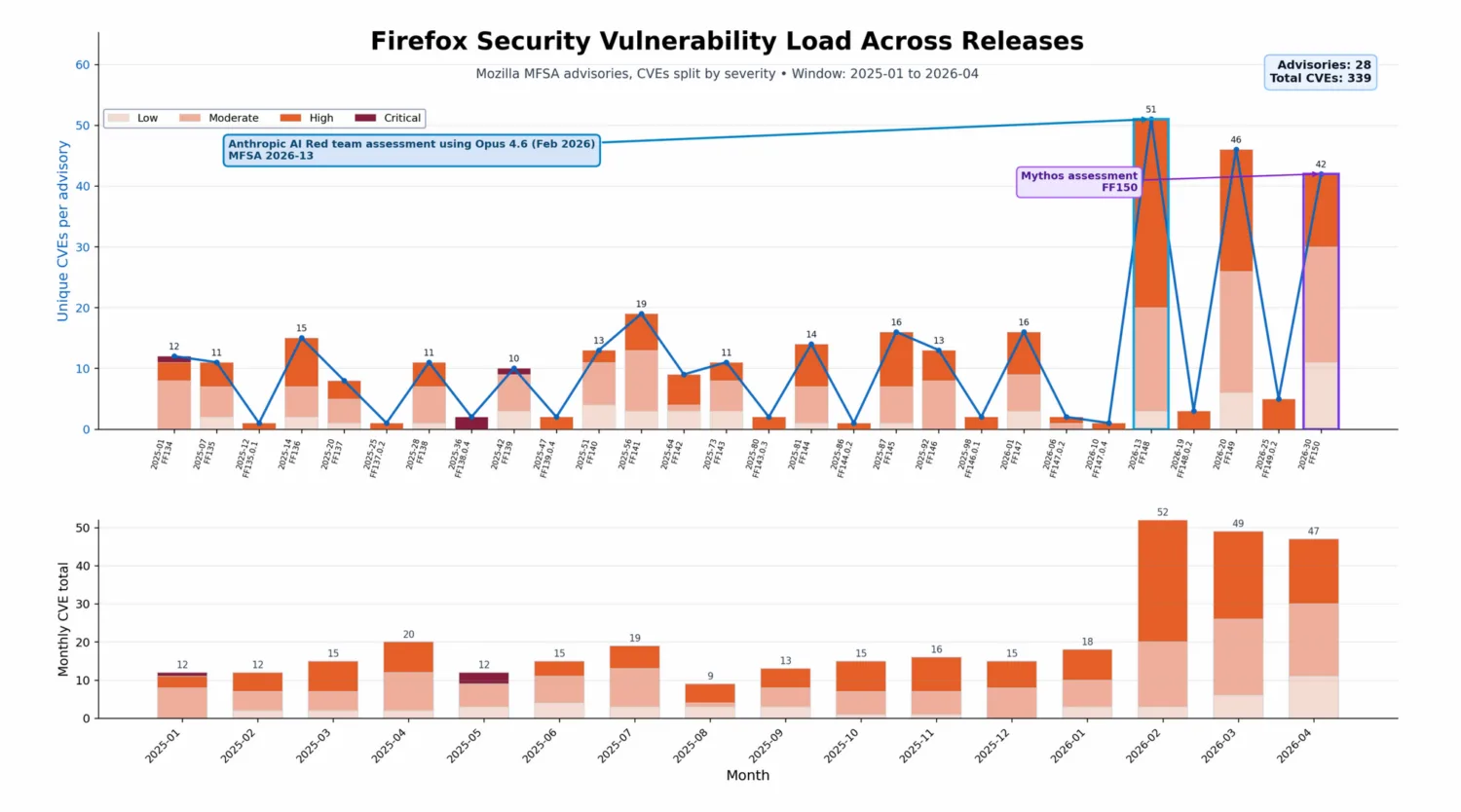
Disclosure volume and operational load
You can see the shift without naming a vendor or model: disclosure volume, scanner output, and exploitation timelines are all moving together. Three effects are already visible across the vulnerability ecosystem.
First, discovery and exploitation evidence are increasing at the same time. VulnCheck reports that 884 vulnerabilities had first-time exploitation evidence in 2025, and that 28.96% of Known Exploited Vulnerabilities (KEVs) were exploited on or before CVE publication.
Second, faster disclosure feeds straight into day-to-day workloads. As issues are formalised into CVEs and pulled into scanners, the backlog grows.
Third, operational pressure compounds because triage capacity does not scale linearly with inputs.
The outcome is a rising remediation backlog and more pressure to prioritise with real context and automation. Better detection alone therefore does not relieve the pressure. Instead, it increases workloads faster than most remediation models can absorb it.
The Red Queen Effect in Security Engineering
The instinctive reaction is to increase remediation speed. Patch faster, scale teams, optimise workflows. This does not work. Even if remediation improves, discovery is accelerating at a comparable or higher rate. The backlog grows regardless.
Increasing speed inside the same operating model does not resolve the underlying scaling problem.
This is the Red Queen effect in practice. You run to stay in place.
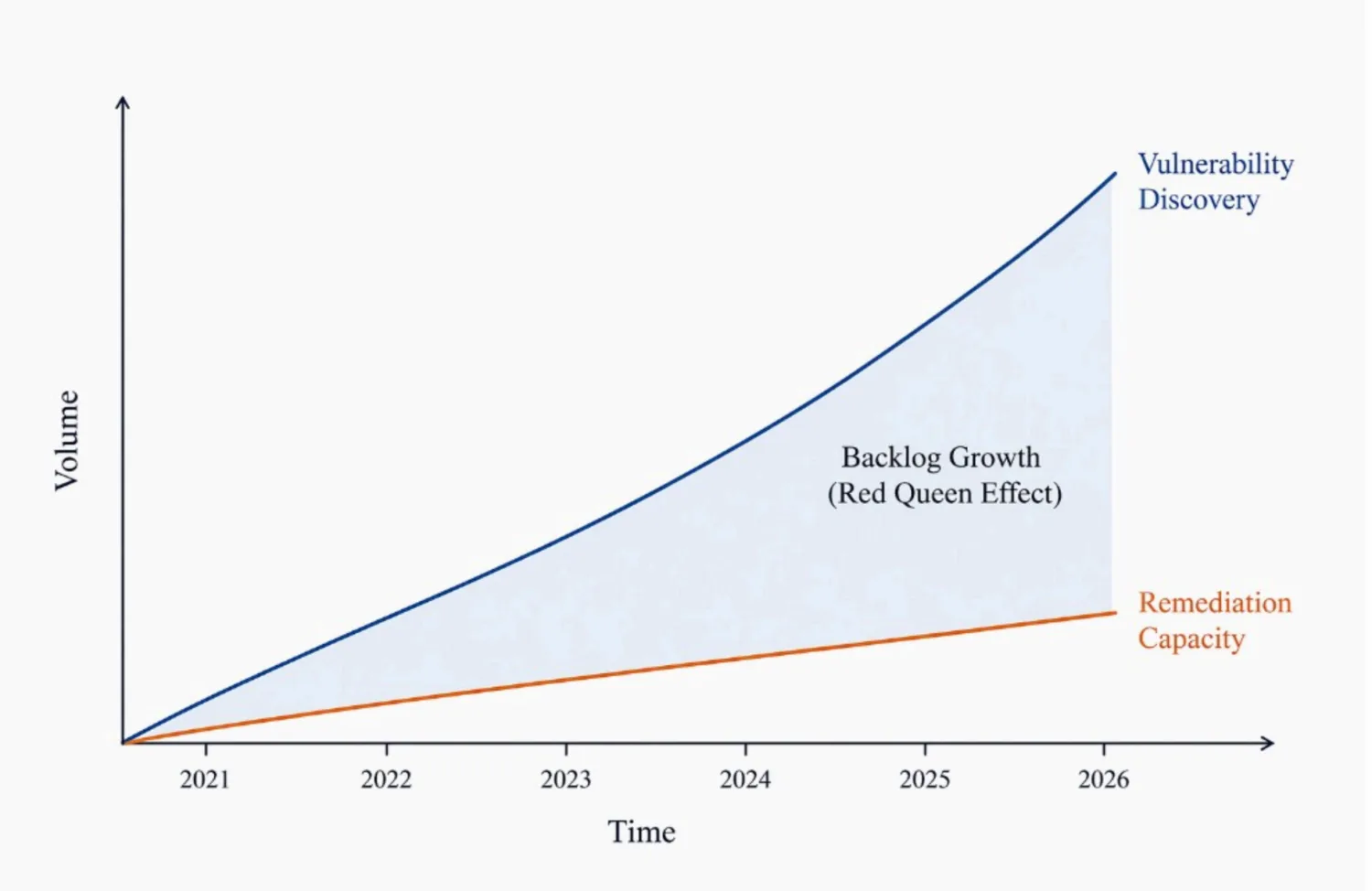
So now we know discovery and exploitation are becoming easier to scale, while remediation remains constrained by finite engineering resources, what do we do?
One practical way to counter this is the use of AI to support faster remediation. Not just better triage, but generation of patch candidates with dependency updates, code changes, and regression checks wired into CI. The goal is not to auto-merge every fix. The goal is to remove low-value manual toil so engineering time is spent on risky or ambiguous cases, while safer fixes can move faster under policy guardrails.
As time-to-exploit windows compress and backlog volume rises, this kind of assisted patching becomes a capacity multiplier rather than a nice-to-have, incrementally deployed under defined governance controls.
Even with strong automation, remediation can still be too slow for the fastest exploit windows. That is why endpoint and runtime protection, increasingly discussed as Application Detection and Response (ADR), should be explored as a second layer on top of auto-remediation when patch timelines cannot reliably keep pace. A strong long-term value is workload protection and runtime isolation that can blunt zero-day impact while engineering teams work the fix.
The Collapse of Supporting Infrastructure
At the same time, the systems supporting vulnerability management are under pressure.
In 2025, continuity concerns around CVE programme administration highlighted ecosystem fragility, even though CISA later stated there was no service interruption and characterised the event as a contract administration issue (see CISA statement, April 16, 2025 and follow-up statement, April 23, 2025).
National Vulnerability Database (NVD) enrichment is no longer guaranteed at scale. Severity scores, affected product mappings, and structured metadata are increasingly incomplete under NIST’s updated prioritisation model (NIST update). Coverage has effectively been reduced, and many CVEs now arrive without the depth of metadata teams previously assumed would be present.
NIST states this shift explicitly:
“Going forward, NIST will add details, or ‘enrich,’ those CVEs that meet certain criteria… CVEs that do not meet those criteria will still be listed in the NVD but deemed as ‘lowest priority’ and will not be immediately enriched by NIST.”
“Going forward, we will no longer routinely provide a separate severity score for those CVEs.”
—NIST, April 2026 update
CVE submissions have grown by 263 percent between 2020 and 2025 (NIST). NIST also indicates that volume pressure is continuing in 2026. This creates a structural problem.
Many triage pipelines were designed for full enrichment coverage; that assumption is now unreliable.
If your prioritisation depends on CVSS alone, it will degrade. Tools and workflows that depend on full enrichment will increasingly return partial or empty prioritisation outputs.
The Inverted Bottleneck: Discovery vs Operationalisation
The bigger change is where programme effort now sits. Historically, finding vulnerabilities was the harder part, and fixing them could follow at a manageable pace. Today, finding vulnerabilities is faster and more repeatable, and often noisy. But turning findings into owned work, fixes, and verified closure is not.
Discovery is abundant; executing on remediation is the constraint. Finding issues increasingly behaves like an automation problem; fixing them still depends on context, ownership, testing, and safe change.
In practice, most of the day is triage, context, ownership, SLAs, and checking that a fix actually landed. That is the bottleneck most programmes were not built for, which is why backlog grows even when detection gets better.
Context Over Severity: The Core Misalignment
AI systems are good at spotting technical severity. They are not automatically aware of business context. This gap is where prioritisation breaks down.
A critical remote code execution vulnerability in an isolated test environment may have negligible real-world impact. A moderate SSRF vulnerability in a payment processing service may represent a significant business risk.
Severity is technical; risk is contextual.
Without context, prioritisation fails. Platforms such as ArmorCode’s Risk Intelligence Graph help close this gap by layering business context (for example, asset criticality and environment mapping) on top of raw technical severity.
How We Approach it in Practice
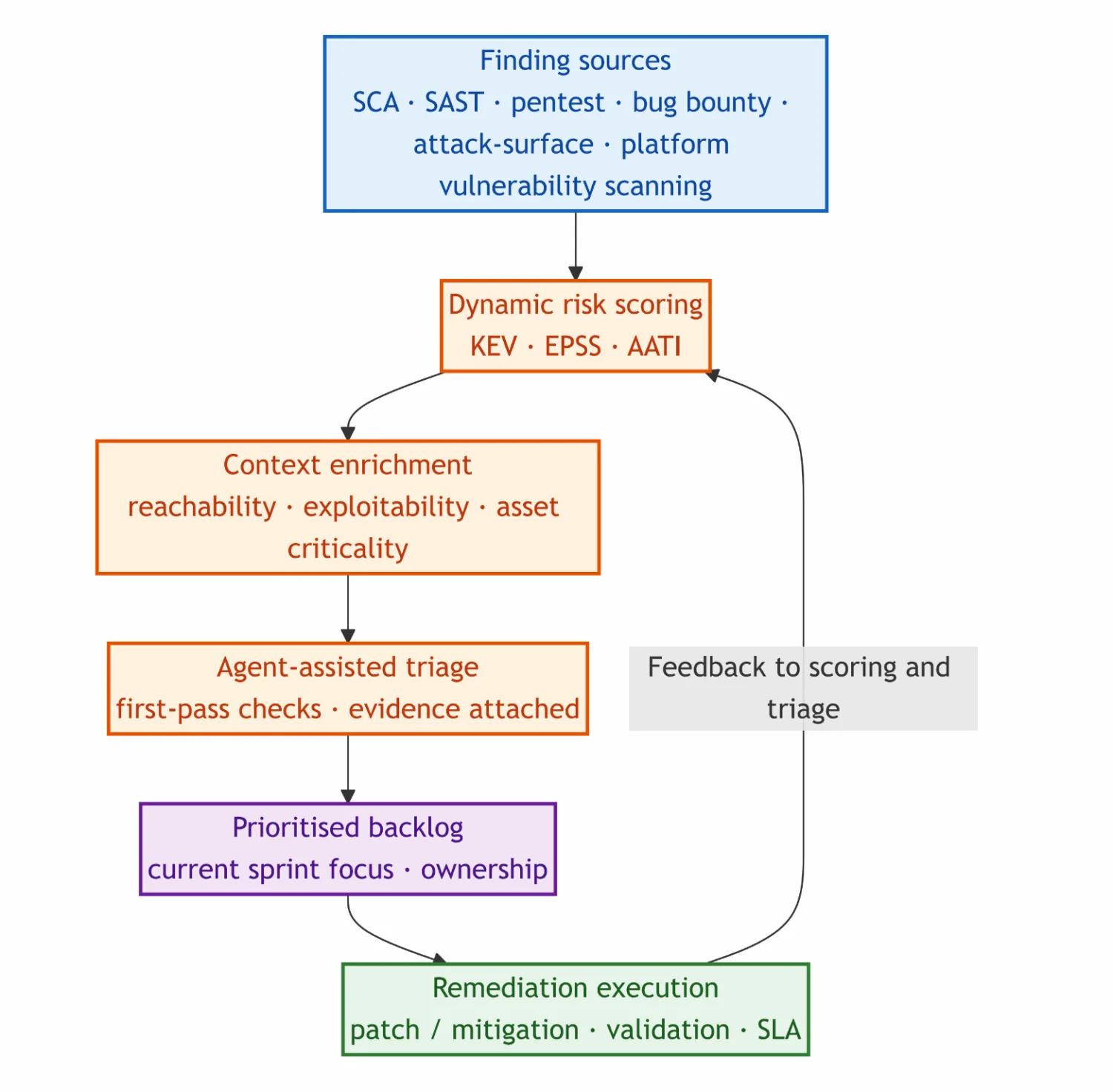
In large-scale enterprise environments, an effective approach is to treat this as an operations problem, not a missing dashboard that reports increasing backlogs.
The approach is straightforward: keep risk scores fresh, triage with exploitability in mind, and push work through to completion.
The sections below are the order we use in practice: refresh risk with Known Exploited Vulnerabilities (KEV), Exploit Prediction Scoring System (EPSS), and similar signals so the backlog reflects what is dangerous now, not only what looked bad when the CVE dropped; add reachability and exploitability; run triage and remediation through a central workflow. Further down we cover agents for first-pass triage with real evidence, what we are trying with retest pipelines, continuous exposure from dependencies, and supply chain compromise before there is a CVE, then how we try to close the gap from finding to fix.
Dynamic Risk Reprioritisation (Beyond CVSS)
The first layer is dynamic risk scoring using KEV, EPSS, and ArmorCode Advanced Threat Intelligence (AATI).
KEV identifies vulnerabilities actively exploited in the wild. EPSS adds probability signals. AATI combines these inputs with additional threat-intelligence context so the score is useful for prioritisation, not only for reporting. Combined, this lets us focus on what matters now, not what looked critical months ago.
We do not rely on static CVSS numbers alone. CVSS remains useful as a baseline signal, but it is insufficient for execution as it does not, by itself, reflect the context of a system.
A CVSS 10 is not automatically a 10 in your environment.
A practical scoring stack layers on additional lenses, for example:
- Known Exploited Vulnerabilities (KEV)
- Exploit Prediction Scoring System (EPSS)
- Threat intelligence
- Reachability and exploitability analysis
- Asset criticality
- Environmental context
In practice, this produces continuously adjusted prioritisation rather than a frozen severity rank. The recent Axios reporting illustrates this clearly.
CVE-2026-40175 was widely framed as a critical “10/10” cloud-compromise scenario, but rapid technical analysis showed the full exploit chain was not realistically reachable in a standard Node.js deployment because runtime header validation blocks the required Carriage Return/Line Feed (CRLF) injection primitive (Aikido analysis, April 2026).
The timing also mattered as this severity debate landed only about two weeks after Axios had already been in the spotlight for the March 31 npm supply chain compromise (Axios post-mortem timeline, Microsoft threat analysis), showing how quickly an ecosystem narrative can amplify urgency before environment-specific risk is validated.
Reachability and Exploitability: Distinct but Linked
Dependency scanning, or Software Composition Analysis (SCA), mostly answers “is this library in the build?” It does not, by itself, answer “can our code reach the vulnerable part?” or “could an attacker use it in our production setup?” That gap produces long, noisy lists with a weak link to real risk. If you never ask whether vulnerable code is actually used, you still get a ranked table, but little help deciding what to patch first.
Reachability narrows the list to plausible code paths. Pairing this with KEV/EPSS-style exploitation signals nudges ordering toward what actually matters, not only what depends on what. This distinction is operationally important because for dependency findings we use four gates in a fixed order. The numbered list below is the full sequence, and the flowchart further down shows the same order visually.
- CVE (or equivalent) on a dependency you ship — otherwise stop or track upstream; do not burn triage on components you do not ship.
- Static reachability — can application control flow reach the vulnerable function (call graph / import level analysis)? That is a possible path, not proof production executed it. If the gate fails: lower remediation priority; document and monitor.
- Deployment exploitability — given this deployment (network exposure, authentication, configuration, compensating controls), is there a viable attack path? If the gate fails: residual or contextual risk; retain and monitor (the “reachable in the static model but not exploitable here” case static lists exaggerate).
- Prioritised remediation — when gate 3 passes: patch, mitigate, or prove compensating controls, and close with evidence.
This gap is visible in day-to-day workflows. Running npm audit can produce long lists of CVEs, but that output does not automatically answer how much your production system is actually affected.
Example (gate 2 fails): a vulnerable function sits in a transitive dependency, but code-level analysis shows the affected method is never reached from your entry points. The package is there; the vulnerable code path is not, so the urgency is lower than the raw CVE row suggests.
Example (gate 3 fails): a Spring4Shell-class CVE is flagged in a Java dependency and the scanner marks it critical. You then check how that service is actually deployed (Tomcat version, exposure, auth) and conclude the chain is not realistic in that environment. You triage on that runtime picture, not on package presence alone.
Example (gate 2 passes, gate 3 often fails): CVE-2021-44228 (Log4Shell). A typical SCA-plus reachability pipeline sees vulnerable Log4j on the classpath and a path from an HTTP handler into logging, so the finding is flagged as reachable RCE. In many deployments triage still fails gate 3 once environment specific conditions are reviewed: only trusted or internal events hit the logger, lookups and JNDI are disabled in log4j2.xml, user input is normalised before it can become a log payload, or JndiLookup is removed from the classpath. Any of these can make the issue reachable yet not exploitable in that environment. The same pattern shows up when advisories list precise preconditions (tag allowlists, module flags, virtual host knobs) that static graphs never see.
Reachability analysis is not limited to build-time graphs. In production, kernel-level observability (for example via eBPF-based tracing) can confirm whether vulnerable code paths are actually exercised on live workloads. This is a different engineering trade-off in terms of deployment, overhead, and data governance. It tightens the link between “present in a dependency” and “observed in runtime”.
As exploitation timelines compress in the public record, runtime visibility and runtime enforcement (detection, containment, selective blocking, and isolation) become a more important complement to patch driven remediation, because they can act when patching lags disclosure.
For agentic applications, where production behaviour is harder to fully predict ahead of release, this detect and-respond layer is likely to become a larger design requirement even before standards fully catch up.
This is not theoretical optimisation but rather a necessary filter based on current CVE volumes. Keep the order: gate 1 (in scope on something you ship), then gates 2 and 3, then gate 4. Production runtime confirmation (tracing or similar evidence that vulnerable code actually executed on live workloads) remains uncommon in practice; where it exists it is a strong complement to static analysis, but most teams still live in build-time graphs plus deployment review for gate 3. AI agents can realistically help with that day to-day chain: faster evidence gathering across gates 1–3, cleaner triage narratives, and in places guided remediation steps. They are not a substitute for instrumented production observability when you truly need execution proof; they reduce friction on the work that happens before that seldom-deployed last mile.
The figure below is the same four gates in order: CVE on shipped dependency → static reachability → deployment exploitability → remediate with evidence. This diagram is how you decide what to patch first.
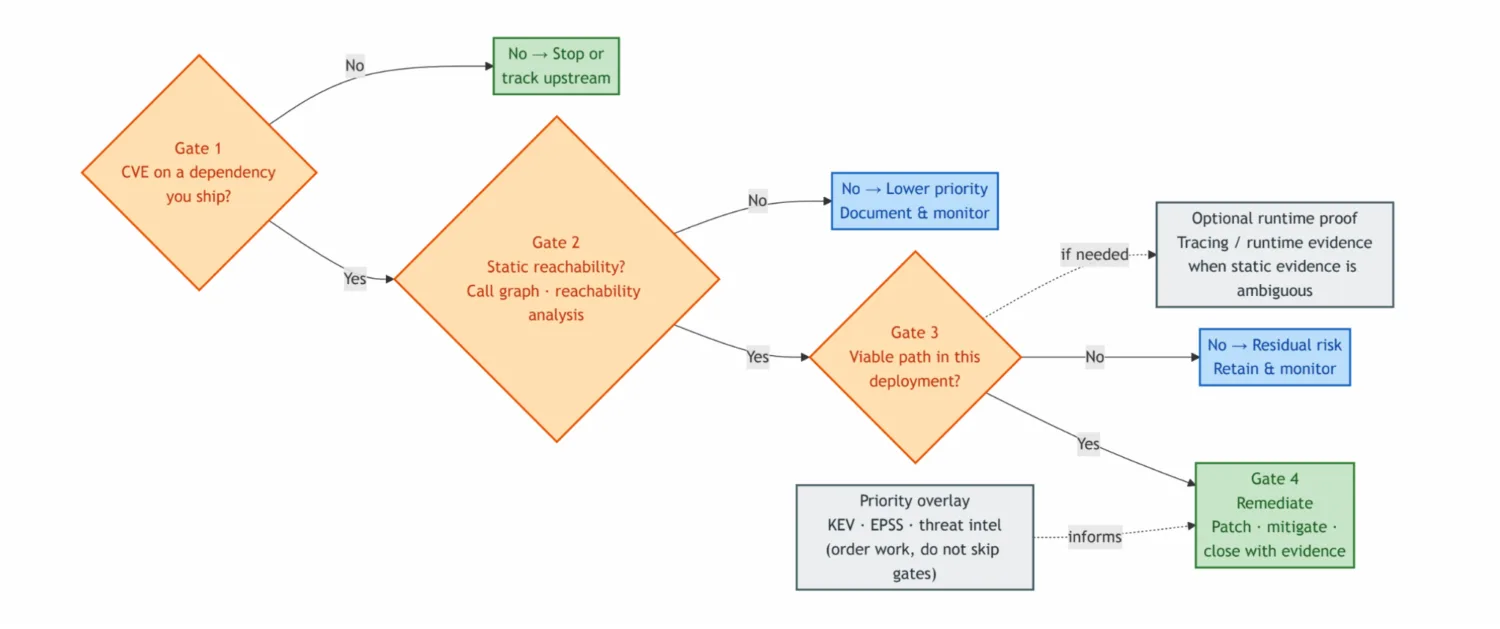
Without context, most findings look equally urgent; with context, you can actually sort the backlog.
Triage and remediation
On top of that scoring, we run triage and remediation with reachability and exploitability baked in. Once the backlog reflects refreshed risk and what fits your environment, we point teams at the highest present risk and use automation where it shortens cycle time.
Internal Programme Observation
In large enterprises the usual problem is not a missing scanner. It is pulling many tools into one place and prioritising risk in a way teams can execute on.
A typical setup aggregates:
- Software Composition Analysis (SCA)
- Static Application Security Testing (SAST)
- Dynamic Application Security Testing (DAST)
- Penetration testing
- Bug bounty
- Attack surface scanning
- Platform vulnerability scanning
- …
In a large enterprise environment analysed during this period, approximately 30% of total recorded findings originated from SCA, with the remaining ~70% distributed across SAST, penetration testing, bug bounty, and external scanning streams (internal operational dataset). This internal distribution is operationally important, because even when SCA is not the majority source, it is large enough to drive backlog growth when triage quality is low.
Outlook prediction = not in that split.
The ~30% / ~70% mix is backward-looking. Mozilla’s red-team note above, about AI-assisted review still finding bugs in code that already went through heavy fuzzing, static analysis, and human review, matches what vendors are now shipping as LLM-integrated SAST. In practice, this is another high-sensitivity pass over familiar source code, and it tends to add net-new findings rather than quietly remove old noise.
Our working expectation for around 2027 is a material increase in SAST-originated intake in the same enterprise queues, which means more triage and remediation work, similar to earlier automation waves (richer dependency graphs, broader dynamic scans, and so on). Programmes already sizing for a Mythos-ready disclosure picture will likely feel this first as deeper queues and overlapping hits across tools, unless they extend intake and enrichment for that channel the way they eventually did for SCA.
To address this, automated triage is introduced. Findings are enriched with context, including reachability and exploitability. This enriched data is fed into a central platform (for example, ArmorCode), enabling dynamic prioritisation.
In the central vulnerability management system, this is executed through runbooks, with per-finding tags used to mark enrichment status (for example, pending, enriched, or needs-review) so teams can see state at queue level without reopening each ticket.
Instead of relying solely on CVSS, this approach combines KEV, EPSS, and internal threat intelligence signals into a continuously updated risk view. This directly impacts how teams plan and execute remediation work.
Practice at the leading edge already extends enrichment beyond SCA and dependency findings into custom AI-assisted pipelines for additional finding types. The patterns are new enough that the operating model is still taking shape, but where quality and governance are in place, enriched output is already viable as a routine prioritisation input to the central vulnerability management (VM) platform.

Agent-assisted triage and skill-backed validation
Scanner output and imported tickets pile up fast, and the same issue often resurfaces across teams. The core triage problem is usually not missing opinions; it is missing repeatable checks and saved evidence next to the finding.
A one-line “false positive” comment rarely helps the next reviewer understand what was actually verified.
Agents help when they run those checks and attach artefacts such as command output, short logs, and API responses directly to the vulnerability platform or linked ticket.
A practical example: an attack-surface tool reports an unexpected open port on a host. Instead of closing from memory, a first-pass workflow runs nmap (or equivalent) with pre-approved arguments and stores the scan summary with the finding, so a human reviewer can confirm service and exposure before disposition. Similar patterns include a targeted curl or browserless fetch to verify whether a Dynamic Application Security Testing (DAST)-reported URL is still reachable after a header or Web Application Firewall (WAF) change, or a read-only configuration extract that confirms a compensating control. This evidence-first model also aligns with ArmorCode capabilities such as Anya and AI Remediation, where agent output can be attached back into the platform workflow.
Skill-based Agent instructions keep this controlled: versioned prompts, explicit tool allow-lists, and a separate path for vulnerability-platform API updates. That gives teams repeatable playbooks and a clear record of which skill version produced which evidence. Humans still own accept, reject, defer, and remediate decisions; the standard shifts from assertion to evidence.
Where feasible, the execution target should be a pull request, not only a ticket. Jira still matters for tracking and governance, but the shortest feedback loop is remediation work that lands as a scoped PR with evidence and, when needed, a linked Jira issue for auditability.
Agentic testing, retest pipelines, and human review
The open question with AI-assisted offensive testing is not whether it will appear, but how much value it adds next to the automated web scans (DAST) and runtime instrumentation (Interactive Application Security Testing, IAST) many teams already run. With code and runtime context, agents can narrow hypotheses, sketch attack paths, and execute checks in hours instead of days in some cases. At its best, the output looks like a well-triaged bug bounty report: clear hypothesis, PoC, replay steps, evidence, and a code pointer (or snippet) showing where the issue is triggered. That is often more actionable for remediation teams than the shorter, tool-centric findings many teams are used to from SAST or DAST alone.
What is still unclear is where each programme should draw the line between analyst-assist mode and heavier pipeline automation.
In practice, this is still experimental and deliberately narrow. One active slice is a retest and first-pass triage workflow for bug bounty and attack-surface findings, where teams run an internal second pass and attach the resulting evidence before human review. This sits next to traditional penetration testing rather than replacing it.
What matters first is simple and practical: show the commands, attach the evidence, and hand off clearly when human judgment is required.
Continuous Exposure: The Backlog Problem
A critical difference in modern environments is that vulnerability exposure is continuous.
With SCA, new vulnerabilities are introduced without any code changes. A dependency that was previously considered safe can become vulnerable due to newly published CVEs. This creates a different operating model from periodic testing. It is not comparable to running a penetration test once per year or around major releases. Supply chain risk can worsen continuously, especially in legacy services with low development velocity, unless backlog remediation is actively maintained.
This leads to passive risk accumulation.
Your security posture can degrade without a single line of code changing.
Legacy systems are particularly affected. Without active remediation, their risk profile worsens over time. This is fundamentally different from traditional models based on periodic assessments.
A Parallel Stream: Supply Chain Compromise Without CVE Assignment
Another risk stream sits beside ordinary CVE work: supply-chain compromise. Examples include trojanised releases, maintainer abuse, and typosquats. These are malware-in-distribution events. They often never look like a “known vulnerable library” row, and they may have no CVE when you still need to act.
Shai-Hulud (npm, September 2025) is a useful case study. ReversingLabs describes it as a self-spreading campaign that injected a malicious bundle.js, stole tokens, and republished trojanised package versions (analysis). Their timeline places patient zero at rxnt-authentication 0.0.3 on 14 September (about 17:58 UTC), with detection on 15 September. A machine-readable advisory row, MAL-2025-47345, appears in GitLab on 16 September (MAL-2025-47345), and CISA’s broader alert naming 500+ affected packages arrives on 23 September (CISA alert). By then, installs and credential exposure could already have occurred.
Two operational lessons follow. First, install-time malware runs wherever npm install runs, including laptops and feature-branch CI, while many programmes still scan mainly mainline or release paths (codecentric on Shai-Hulud and SCA). Second, CVE-first views are incomplete for this class of incident:
GitHub’s global advisory API excludes malware entries unless callers set type=malware (GitHub REST API: global security advisories), and NVD/CVE may have no corresponding row. A “clean” composition report is therefore not proof of a clean dependency tree.
SCA and malware supply-chain threat intelligence should be one capability: same lockfile or SBOM, same CI gates, one remediation path, so trojanised packages do not fall between a “CVE scanner” and an intel feed nobody wired in.
That widens the operational surface: not only app dependencies but runners, ephemeral CI, registries, and automation identities that can leak tokens or signing material. Programme-wise, keep known-CVE remediation and package trust/containment as parallel workstreams, but use one inventory and one workflow where possible. Threat feeds, install-time monitoring, and reachability-aware checks already catch what CVE only SCA misses when malicious versions move before a CVE exists; the winning pattern is to merge those signals, not bolt on a second silo.
Closing the Loop: From Discovery to Remediation
The key challenge is closing the loop between finding and fixing. In practice, discovery quality alone is insufficient. Programmes need an execution layer (in that case our centralised vulnerability management system) that adds:
- Business context
- Ownership mapping
- Workflow integration
- SLA tracking
- Remediation validation
What actually matters in tooling includes:
- Graphs or views that tie vulnerabilities to asset importance and threat intel
- AI-assisted summaries that an engineer can use without rewriting them for leadership Remediation workflows wired to Jira
- PR-first remediation workflows that can automatically open or update Jira links when policy requires it Basic governance for AI-assisted discovery (who ran what, what was promoted to a ticket)
The real win is increasingly in remediation decisions, not raw discovery volume.
What Needs to Change
The direction is clear. AI-driven discovery will continue to scale. The volume of vulnerabilities will increase. Supporting infrastructure will struggle to keep up. Security programmes need to adapt.
This includes:
- Moving away from static severity-based prioritisation
- Risk models that include real context (assets, exposure, ownership), not only CVSS Automating triage and remediation workflows
- Integrating discovery with operational execution so findings flow directly into owned tickets, remediation, and verified closure
- Shifting focus towards runtime visibility and control
- Designing triage so evidence travels with the finding, not only a comment that closes the ticket Running SCA and supply-chain signals (including pre-CVE cases) as one programme
The practical objective is not to outpace volume, but to adapt operating models to sustained volume.
Discovery is cheap and noisy; getting fixes shipped and verified is where programmes win or lose. Good security here means honest prioritisation, enough context to decide, and a path from ticket to verified fix, not a longer list of findings.